
This sample contains the first two brief chapters from the book followed by brief excerpts from other key chapters
-
The paperback edition contains:
-
✓ 9 chapters in 222 pages
-
✓ 130 graphics, charts & tables
-
✓ many insights and a few jokes


Why Read
This Book?
Life is short. Time is precious.
This chapter explains why you should read this book and how it can help you with any computer performance problem, now or in the future.
Good News!
Performance work is a great career because the only constant in this universe is change. Everything (hardware, operating systems, networking, applications, users, corporate goals, org charts, priorities, and budgets) changes over time and with change comes new performance challenges. There are always things to do, things to learn, things to prepare for, and experiments to run. Good performance work can save the company and put your kids though college. Yay!
Bad News...
Most computer performance books are fairly useless for solving your problems. Why? Because:
-
•Some have hundreds of pages of very difficult math that most people can’t do and most problems don’t require.
-
•Many focus on a specific version of some product, but you don’t have that version.
-
•There is no performance book for a key part of your transaction path.
-
•There are so many different technologies in your transaction path; to read all the necessary books would take longer than the average corporate lifetime.
-
•Almost all manuals about a specific version of a technology were written under tremendous time pressure at about the same time the engineering was being completed; thus the engineers had little time to talk to the writers. The result is that these books document, but they don’t illuminate. They explain the what, but not the why. They cover the surface, but don’t show the deep connections.
So, How Is This Book Different?
Should you accept the bad news, stop reading here and switch careers? I don’t think so.
There are some important differences in this book you should consider before deciding.

What I’m about to tell you will work for any collection of computers, running any software that has ever been built. It will continue to be useful 100 years from now when today’s technology, if it runs at all, will look as quaint as a mechanical cuckoo clock. How’s that work?
Simple. The fundamental forces of the universe don’t change over time.
Whether you are studying the slow response time of a computer, the root cause of a traffic jam, or why you are always in the slowest line, understanding those forces gives you a big insight into why this is happening. They help you make sense out of the performance meters you do understand and help keep you from making big mistakes.
It Works With Any Meters You Have
This book gives you tools to explore any available metering data. It shows you how to use the scientific method to decipher what they mean and how to find patterns in the raw data. These patterns can tell you useful things about what’s going on inside the giant black box that is your computing world. With this book you can turn raw data and weird meters into solid information that can solve and/or prevent serious problems.

It Helps You Find and Focus
Many parts of this book help you solve the diversity and complexity problems mentioned earlier by helping you quickly determine that large chunks of your computing infrastructure are not the problem. This rapidly focuses your company’s full and undivided attention on the small part of your computing world (System Z) that is causing the performance problem.

Once focused, a large fraction of everyone’s effort is spent working in the right place and on the right problem. Now, the right experts can be consulted and business decisions can be made to fix or work around the problem.
The Math is Doable
All the math is boiled down to a few simple, wildly useful formulas. The most complex formula I use is:
R = S / (1 - U)
If you can replace S with the number 2 and U with the number 0.5 and calculate that R is equal to (spoiler alert) 4, then you have all the math you need for a long career in performance.
It Helps With The Human Side Of Performance

Having worked many performance problems from problem discovery, through solution presentation to senior management, and then on to problem resolution, I’ve made a few mistakes and learned a few tricks. They are all in here.
It Gets To The Point
This book is concise, useful, and occasionally funny. It gives you the tools needed to explore, and discover the hidden truths about your computing world. With it, and some work on your part, you’ll be able to solve performance problems and to walk into the CIO’s office with confidence.
Who Am I To Make These Claims?

If you are a person who is only impressed with academic qualifications then I have few to offer you. I went to college with no particular plan, other than to have a good time. I had three majors (Wildlife Biology, Botany and Computer Science) but I have no degree as I left college when I ran out of money and got my first job in the computer industry.
I’m a practical guy that listens well, seeks out useful insights, tools and techniques. I’ve read a few computer performance books and found a few good things here and there. Mostly I’ve learned from other performance wizards, programmers, system administrators and a few generally smart people I’ve known. If it worked for them, then I’d figure out how to make it work for me.
I’m also good at explaining things clearly. I’ve had plenty of practice in my standup teaching as well as when working with customers. Clarity is essential when explaining to senior management that they need to spend large amounts of money. An engaging style is essential when teaching multi-day classes, especially just after lunch. I like people and if I couldn’t make my classes useful, interesting, and relevant, then I would have stopped teaching a long time ago.
The seed idea of this book came from Anybody's Bike Book by Tom Cuthbertson. Back in the 70’s he wrote this wonderful little book about repairing literally any bicycle. Forty years later, it is still in print and still useful.


Right Tool
For The Job
There are the four fundamental tools used to explore and solve performance problems.
This chapter discusses what they are, when to use them, and how these tools
interact.
The Four Tools of Performance
Your business depends on a collection of computers, software, networking equipment, and specialized devices. There are parts of it that you control and can directly meter. There are many other parts that you don’t control, can’t meter, and have no clue how they do their work. Furthermore, there are limits placed on you due to politics, time, budget, legal restrictions, and the tools you have available.
All companies have an internal language and shorthand terms they use when describing the subset of the entire computing universe that determines their customer’s experience. Here we will just refer to that subset as the system. As a performance person you study this mysterious system and ask three questions: “What is the system doing now?”, “Why is the system running slow?”, and “Can the system handle the upcoming peak load?” To answer these questions you open your tool bag and discover four tools. Let me introduce you to them...
Performance Monitoring
Ignorance is not bliss.
Performance monitoring is about understanding what’s happening right now. It usually includes dealing with immediate performance problems or collecting data that will be used by the other three tools to plan for future peak loads.
In performance monitoring you need to know three things: the incoming workload, the resource consumption and what is normal. Without these three things you can only solve the most obvious performance problems and have to rely on tools outside the scientific realm (such as a Ouija Board, or a Magic 8 Ball) to predict the future.
You need to know the incoming workload (what the users are asking your system to do) because all computers run just fine under no load. Performance problems crop up as the load goes up. These performance problems come in two basic flavors: Expected and Unexpected.
Expected problems are when the users are simply asking the application for more things per second than it can do. You see this during an expected peak in demand like the biggest shopping day of the year. Expected problems are no fun, but they can be foreseen and, depending on the situation, your response might be to endure them, because money is tight or because the fix might introduce too much risk.
Unexpected problems are when the incoming workload should be well within the capabilities of the application, but something is wrong and either the end-user performance is bad or some performance meter makes no sense. Unexpected problems cause much unpleasantness and demand rapid diagnosis and repair.
The key to all performance work is to know what is normal. Let me illustrate that with a trip to the grocery store.

The other day I was buying three potatoes and an onion for a soup I was making. The new kid behind the cash register looked at me and said: “That will be $22.50.” What surprised me was the total lack of internal error checking at this outrageous price (in 2012) for three potatoes and an onion. This could be a simple case of them not caring about doing a good job, but my more charitable assessment is that he had no idea what “normal” was, so everything the register told him had to be taken at face value. Don’t be like that kid.
On any given day you, as the performance person, should be able to have a fairly good idea of how much work the users are asking the system to do and what the major performance meters are showing. If you have a good sense of what is normal for your situation, then any abnormality will jump right out at you in the same way you notice subtle changes in a loved one that a stranger would miss. This can save your bacon because if you spot the unexpected utilization before the peak occurs, then you have time to find and fix the problem before the system comes under a peak load.
There are some challenges in getting this data. The biggest and most common challenge is in getting the workload data. The Performance Monitoring chapter will show you how to overcome challenges like:
•There is no workload data.
•The only workload data available (ex: per day transaction volume) is at too low a resolution to be any good for rapid performance changes.
•The workload is made of many different transaction types (buy, sell, etc.) It’s not clear what to meter.
With rare exception I’ve found the lack of easily available workload information to be the single best predictor of how bad the situation is performance wise.

“The less a company knows about the work their system did in the last
five minutes, the more deeply screwed up they are.”
– Bob’s First Rule of Performance Work

What meters should you collect? Meters fall into big categories. There are utilization meters that tell you how busy a resource is, there are count meters that count interesting events (some good, some bad), and there are duration meters that tell you how long something took. As the commemorative plate infomercial says: “Collect them all!” Please don’t wait for perfection. Start somewhere, collect something and, as you explore and discover, add this to your collection.
When should you run the meters? Your meters should be running all the time (like bank security cameras) so that when weird things happen you have a multitude of clues to look at. You will want to search this data by time (What happened at 10:30?), so be sure to include timestamps.
The data you collect can also be used to predict the future with the other three tools in your bag: Capacity Planning, Load Testing, and Modeling.
Capacity Planning
Capacity planning is the simple science of scaling the observed system so you can see if you have enough resources to handle the projected peak load, but it only works for resources you know about.
Capacity planning is like a pre-party checklist where you check if there are enough: appetizers, drinks, glasses, places to sit, etc. Assuming you know how many guests will show up and have a reasonable understanding of what they will consume, everything you checked should be fine. However, even if you miss something, you are still better off having planned for reasonable amounts of the key resources.
Capacity planning starts by gathering key performance meters at a peak time on a reasonably busy day. Almost any day will do, as long as the system load is high enough to clearly differentiate it from the idle system load. Then ask the boss: “How much larger is the projected peak than what I have here?” Answers like: “2X” or “about 30% more” are the typical level of precision you get.
Now scale (multiply) the observed meters by the boss’s answer to get the projected peak utilization.
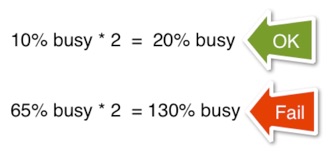
Often you will then find a resource, or two, that will be too busy at your projected peak. In that case, the load has to be handled by:
•Moving it to a faster machine
•Splitting it over several machines
•Reengineering the application for efficiency
In my experience, the application is rarely reengineered unless the inefficiency is egregious and the fix is easy and obvious. In most situations, people tend to value application stability more than the money they will spend to solve the problem with more hardware.
Capacity planning can be that simple, but there are a few more things you need to consider.
Even though you base your projections on one peak day, you should look at the data over a period of a few days to a few weeks. This gives you a clear picture where the usual daily peaks are and if there are things going on at odd times that you have to factor into any changes you propose.
Capacity planning can show you how busy key resources are at peak load, but it can’t tell you about response time changes as the load increases. Even if you had perfect metering, doing the math would be a staggering challenge and, even, then you’d be gambling the business on reams of calculations. I’m very sure the CIO looking at all this complex math would feel very uneasy betting his or her job on these calculations.
Many key resources do not have a utilization meter, and the ones that do can lie to you. These resources take a little more work and creativity to capacity plan for, but this is completely doable.
Capacity planning is a good first effort at dealing with a future peak load. It can be done in a few days, presented in a few slides and prepared with few additional costs or risks. If you need more confidence in your plan, or you need to hold the response time down to a reasonable level, or if the future you are planning for includes significant changes to the transaction mix or vital systems, then you need to do either Load Testing or Modeling. They sound a little scary but, as Douglas Addams once wrote, “Don’t Panic.”
Load Testing
Load testing is the art of creating artificially generated work that mimics the real work generated by the real users. The overall load starts off low and then increases in stages to the point where you achieved your goal or you fail because some resource has hit a limit and has become a bottleneck. When that happens, throughput stops increasing, response times climb to an unacceptably painful place and things break.
Load tests depend on good performance monitoring to keep an eye on critical system resources as the load builds. For any test you need to know how much work you are sending into the system, the throughput and response time for the completed work, and how the system resources are responding under that load. Let’s look at an example:

In the above load test our goal rate was 250 transactions/sec. The system worked fine at 50/sec but bottlenecked at 118 transactions/sec with a very high response time, and the CPU clearly exhausted at 97% busy. As we say in New England: You can’t get there from here.
Now you can retest this system increasing the load in finer steps between 50 and 120 transactions/sec looking for the point at which the numbers start to become unacceptable.
For a load test to be really useful it must test the entire part of the transaction path that you care about. If your product is your website then you need to test from where your users are: all the way in and all the way back to where they live. If you (and your boss) only have responsibility for a small subset of the entire transaction path then that’s all you really need to test. The three big keys to a successful load test are:
•Make the generated work look like what you expect during the projected peak load
•Design the test to test the whole transaction path
•Increase the load in stages, looking for the point where things go bad
Load testing can also use capacity planning tricks. If you only got half way to your goal before you hit a bottleneck, then every measured resource is going to be doing twice the work once you fix the current bottleneck. So take all the peak measurements and double them to get a good idea of what you are likely to run out of as you push the test to the goal load.
Load testing can also help you find where subsystems break, and isolate the effect of one transaction type. Imagine your workload is an even mix of Red and Blue transactions, but it is the Blue transactions that really exercise some key component of your computing world. Create a load test that sends in all Blue transactions and you can collect the data you need without the interference of the Red transactions.
Load testing can tell you many interesting things, but it can only give you data on the computing infrastructure you have now. To use a metaphor, running a race tells you about your current aerobic capacity, not the capacity you will have after six more months of training.
If you need to predict a future that is different from your present, then you need to model. To model, you are going to need the data you collected with performance monitoring and maybe some data from load tests.
Modeling
Modeling computer performance may be unfamiliar to you, but is should not be frightening. Everyday, in companies all over the world, regular people build simple models that answer important business questions.
Here are a few general truths about modeling that may surprise you:
•A simple, but very useful model, can be created with a piece of paper in just a few minutes.
•You can build amazing models with just a spreadsheet.
•A serious response time model for a big, commercial, multi-tier application takes 2-4 weeks of work to create.
•Your model doesn’t have to be perfect, just good enough to answer the question(s) being asked.
•You don’t need to model the detailed program logic or every possible transaction.
•You don’t need a super computer, just a humble laptop, to build and run a model.
•Since any incoming workload and complex application infrastructure can be simulated, you save a ton of time and money on test hardware and load generation tools.
•Regular people, who are not math wizards, can create the full range of useful models. This isn’t rocket science; it’s bookkeeping.
When your boss asks you to predict future performance of some application, first see if you can do a simple capacity plan. If circumstances change so much that you lack confidence in that prediction, then try modeling. Examples of big changes that preclude simple capacity planning might be things like, large application or middleware changes or a big change in the incoming workload. Modeling is the only way to project the performance of an application in the design stage where there is no performance data to scale.
In performance work there are really only two possible situations. Either you can directly measure the performance of a live system under load, or you have to guess about a theoretical future situation. You must accept that:
•Any model is just a detailed guess.
•To some degree, your guess will be wrong.
•The farther out you predict, the less accuracy your model will have.
How accurate does a model need to be? The flip answer is: accurate enough. A useful answer is: accurate enough to answer your question with a reasonable margin of safety.
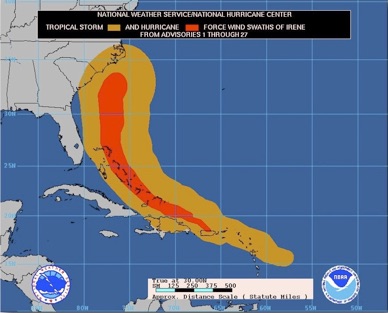
This model of Hurricane Irene is accurate enough for anyone with a house on the Gulf of Mexico and it looks hopeful for Florida’s Atlantic coast as well.
In a computer context, imagine your model shows that at peak load this server’s CPU is 20% busy. It doesn’t take a genius to understand that your model could be off by a lot and the server would still have plenty of CPU power left. The closer to the utilization limit (or the projected storm track), the more precise you have to make your model.
Unfortunately, the above model of Hurricane Irene, at that moment, could not see far enough into the future to predict the devastating flooding Irene would cause in my home state of Vermont. All models have limits.
If you respect these limits, modeling is doable, useful and has its place when you are asking questions about the future.


Useful Laws
. . . and Things I’ve Found To Be True
Some things are true everywhere. This chapter gives you the keys to understanding all computer performance problems and provides an important foundation for the next four chapters.
Excerpt: Seven Insights Into Queueing Theory


Performance Monitoring
“You can observe a lot by just watching.” - Yogi Berra
This chapter focuses on how to meter and how to get the most out of your metering data.
Excerpt: What You Don’t Know About a Meter


CapacityPlanning
“Prediction is difficult, especially about the future.” - Yogi Berra
This chapter shows you how to gain confidence you will make it smoothly though a projected future peak load by scaling up your current observed load.
Excerpt: The Four Numbers of Capacity Planning


Load Testing
“In theory there is no difference between theory and practice.
In practice there is.” - Yogi Berra
This chapter gives you practical advice on how to load test an existing application to see if can really handle the upcoming peak.
Excerpt: Load Testing Basics


Modeling
“The future ain't what it used to be.” - Yogi Berra
This chapter dispels the myth of modeling complexity and shows how modeling performance can save you a lot of time and money.
Excerpt: Modeling Is Doable and Useful


Presenting Your Results
“I never said most of the things I said.” - Yogi Berra
This chapter teaches you how to present your results so that they are understood and are believable.
Excerpt: Presenting Performance Results


Bob’s Performance Rules
"It's like deja vu all over again." -Yogi Berra
This chapter reviews and expands on the performance rules sprinkled in this book.
Excerpt: Coming Soon